
Hardware Arbitrage with Luminal and Positron AI
Luminal compiles off-the-shelf models to Positron Atlas and Nvidia Blackwell to unlock fast and cheap inference across heterogeneous chips.


Background
Today nearly all inference demand is met with GPUs designed for a wide-variety of workloads. The flexibility of GPUs has been both a great strength, allowing many different models to run on the same chips, as well as a weakness by forcing workloads with very different characteristics to run on the same hardware. Some workloads are inherently memory bound and require large memory bandwidth, like LLM decoding, while others are compute bound and require large amounts of flops, like LLM prefill or diffusion.
Matching hardware to workloads allows us to better balance hardware utilization and achieve better inference performance and economics. However, when moving off of pure GPU inference, a significant difficulty emerges: models need to be rewritten for different accelerators, often times with an entirely new programming model. This process usually requires engineers with deep expertise in a specific architecture, who are often hard to find. Large engineering teams at frontier labs often spend many months porting a single model to a new platform.
This is the main reason we set out to take a compiler-first approach from day 1. By owning the compiler, we can control the entire process, from model definition through optimization and lowering down to exact hardware instructions. This gives us unmatched flexibility in which accelerators we can target, and by leveraging large-scale search we can lean on our compiler to find optimized implementations on a wide variety of hardware architectures.
Why Positron?

When evaluating hardware partners for our first non-GPU compiler backend, Positron fit cleanly into our vision of heterogeneous inference, complementing GPUs and providing a new landscape to explore with our search-based compiler.
They have a clear focus on what matters most to them: memory bandwidth utilization. While other chips offer large bandwidth, it’s often quite hard to access and most inference runs at small fractions of total bandwidth utilization. With a simplified programming model and hardware that made memory accesses explicitly controllable, writing code to access the device’s full bandwidth is much more straightforward than on GPUs. This made them a clear choice for bandwidth-heavy workloads, such as decoding.
Given a Positron Atlas system as a far different programming model compared to a GPU, it provides an enticing target for testing the robustness of the Luminal compiler.
The Software Bottleneck in AI Hardware
To date, only one company has successfully achieved mass-market software adoption for a comprehensive AI accelerator software stack: Nvidia’s CUDA. Despite colossal market incentives, creating a comprehensive mapping from user workloads to complex hardware without unnecessary overheads is hard. The startup graveyard is full of hardware companies underestimating the difficulty of building a software stack both bespoke to their hardware and integrated with the rest of the ML software ecosystem.
In building Luminal we knew if we got the abstractions right, if our search was powerful enough, we could compile user-provided workloads straight from Pytorch to achieve speed-of-light performance across wide varieties of hardware. In doing so, Luminal is the quickest way for a new chip to start running models and achieve far higher performance than any “compatibility layer”. In the long run if we embrace the bitter lesson hard enough it should even outperform any hand-crafted or agent-crafted implementation through the power of large-scale kernel search.
Our luminal_tron backend is our first public demonstration of the flexibility of this technology.
The Positron Atlas Architecture
Atlas is a set of systolic array accelerators arranged in a star-topology, with a host CPU in the middle. Achieving high-performance inference requires constant overlapping of matrix-multiplies, weight loading, and host-side element-wise operations.
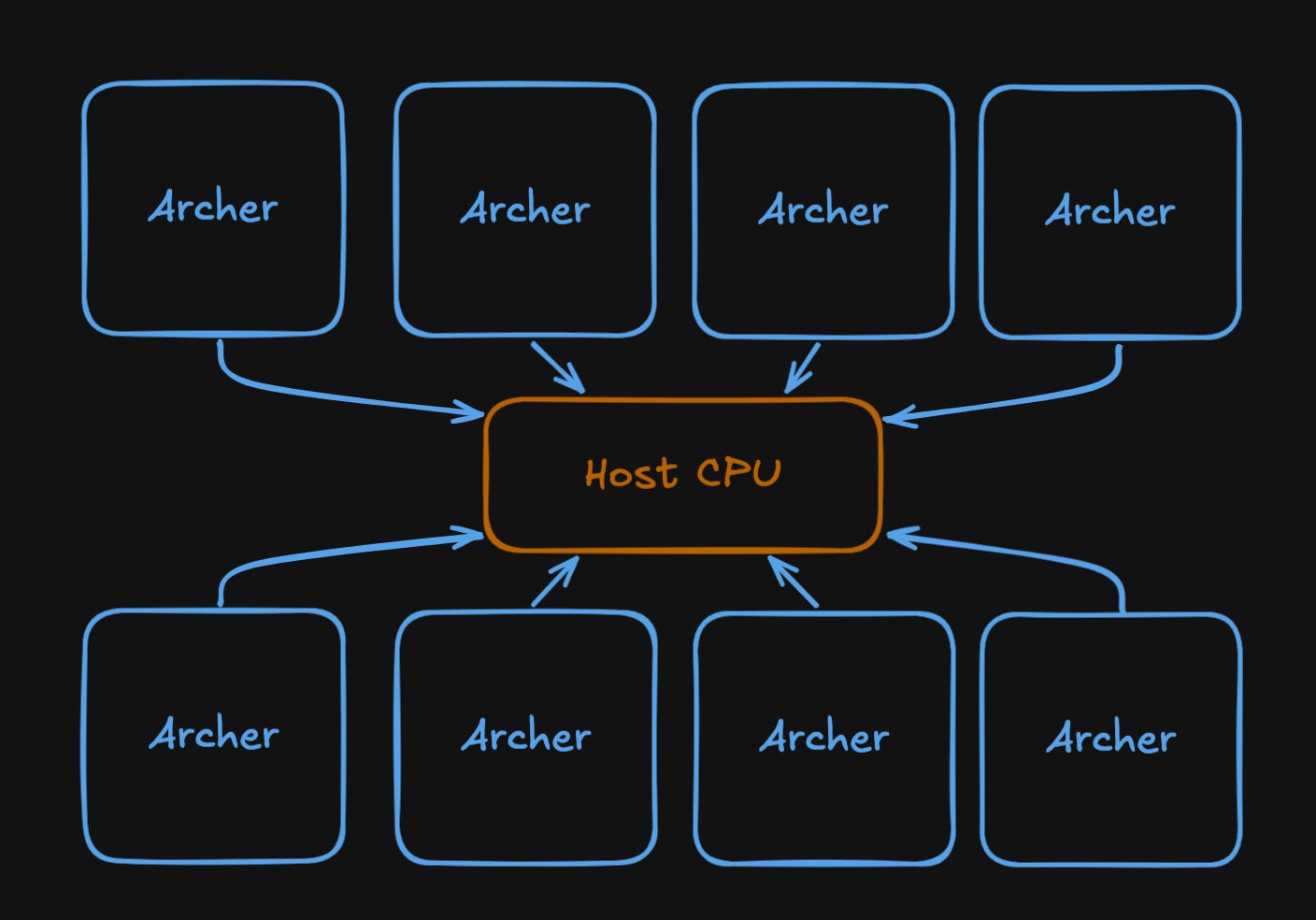
Each Archer device contains a systolic array, SRAM buffers, and 32GB of HBM containing model weights. Compute-heavy operations such as dense matrix multiplies or attention operations are offloaded to the Archer devices, while elementwise operations happen on the host CPU.
Achieving high performance means heavily overlapping operations happening on the devices with those happening on host threads. Doing this requires Luminal to generate a heavily multi-threaded program that uses many CPU cores in parallel to overlap host-side compute and device-side work dispatching. Searching over the space of possible overlapping schedules is key to Luminal automatically finding schedules that maximize hardware utilization.
Inference is fundamentally heterogeneous
When a new prompt arrives at an inference endpoint, the first part of the inference workload is called prefill, requiring the transformer model to ingest the full prompt to generate a KV cache and the first output token. Because the full prompt is supplied right from the start, each token can be processed in parallel. This requires the weights of the model to only be loaded once, no matter how large the prompt is. So memory bandwidth is roughly constant, even on longer prompts (with the exception of attention), while the compute required for prefill scales roughly linearly. This means prefill is usually compute-bound, limited by the amount of compute available. This fits well on standard GPUs, which use powerful tensor cores to deliver petaflops of compute.
On the other hand, once prefill is complete and the first token and KV cache have been generated, the process of generating every subsequent token is called decode and requires loading the entire model’s weights into compute units to get each token out. Since each token relies on all tokens before it, this process is purely sequential, meaning we can’t share weights across tokens in the sequence dimension like we do in prefill. This results in decode being entirely limited by the speed at which we can load the model’s weights into the compute units, also known as bandwidth-bound. It is this regime we target with Positron Atlas.
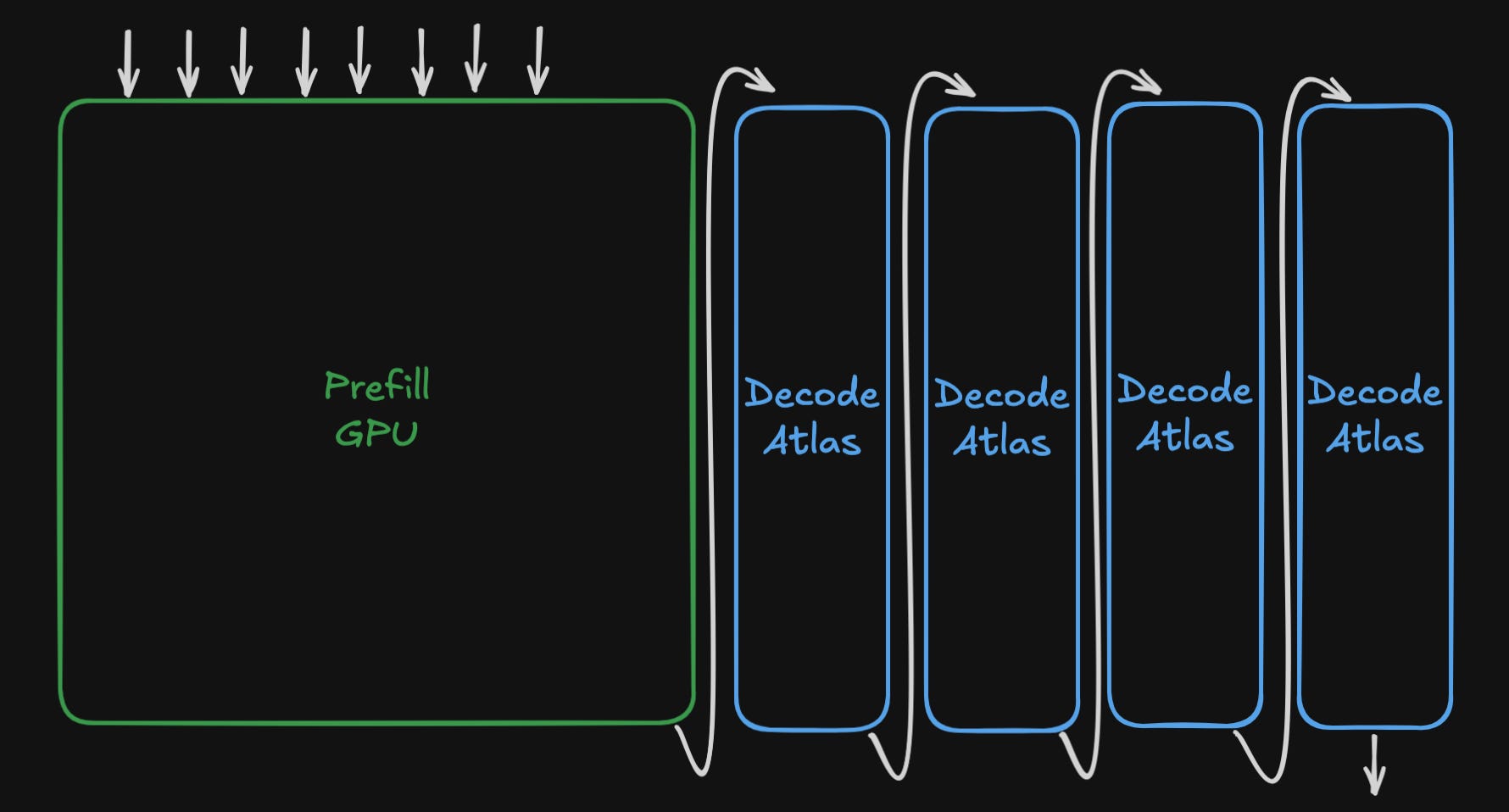
Between the phases, we transfer the KV cache between the GPU and the Atlas system before decoding can begin.
We chose to compile the prefill phase to a CUDA graph and run on an H100, and compile the same model’s decode phase to Atlas. Even though these hardware platforms work entirely differently under the hood, Luminal compiles the exact same model definition with a single-line code change:
import torch, luminal_cuda, luminal_tron
# Compile for GPU
prefil_model = torch.compile(model, backend=luminal_cuda)
# Compile for Positron
decode_model = torch.compile(model, backend=luminal_tron)A more technical post discussing results and metrics is coming soon, with precise performance benchmarks achieved on both prefill and decode.
Conclusion
The Luminal compiler allows us to take off-the-shelf models and compile them automatically to a variety hardware backends. We’ve partnered with Positron AI to bring Atlas up as a compiler backend, bringing the full range of Luminal-supported models to Atlas. We also combine Atlas and Blackwell to demonstrate disaggregated inference across heterogeneous hardware.
By targeting hardware that fits workloads tightly, Luminal greatly improves performance and cost of inference. As inference becomes an increasing bottleneck in AI deployment, purpose-built hardware is quickly becoming the norm. In this post we’ve described how Positron’s Atlas, with the Luminal compiler, fits into this world. Luminal, the unified software stack capable of accessing the full performance of each accelerator, is key to unlocking this future.
Sounds very interesting, looking forward to the detailed blog !